Introduction
Cet article explique comment mettre à niveau Ceph d'Octopus vers Pacific (16.2.4 ou supérieur) sur Proxmox VE 7.x.
Pour plus d'informations, consultez les notes de version
Le cas pratique utilise la mise à jour depuis Octopus 15.2.13 vers la dernière en date de pacific.
Le cluster est composé de 3 noeuds ayant chacun :
- 6 SSD 1To
- 1 vlan d'interconnexion des 3 machines en cluster dédié à ce rôle (réplication ceph)
Pré-requis
Nous supposons que tous les nœuds sont sur la dernière version Proxmox VE 7.0 (ou supérieure) et Ceph est sur la version Octopus (15.2.13-pve1 ou supérieure).
- La version Ceph est 15.2.x Octopus
Sinon, veuillez consulter le guide de mise à niveau de Ceph Nautilus vers Octopus.
Remarque : alors qu'en théorie, il est possible de passer directement de Ceph Nautilus à Pacific, Proxmox VE ne prend en charge que la mise à niveau d'Octopus vers Pacific.
- Déjà mis à niveau vers Proxmox VE 7.x
Mise à jour Proxmox VE (PVE) 6.4-11 vers 7.0-11
Si non, veuillez consulter le guide [[Mise à niveau de 6.x vers 7.0]].
- Le cluster doit être sain et fonctionnel !
Activer le protocole msgrv2 et mettre à jour la configuration Ceph
Si vous ne l'avez pas déjà fait lors de la mise à niveau vers Nautilus ou Octopus, vous devez activer le nouveau protocole réseau v2. Émettez la commande suivante :
Voir sur quelle version nous sommes :
root@hpv-prx-01:~# netstat -lptune | grep 6789
tcp 0 0 10.254.94.196:6789 0.0.0.0:* LISTEN 64045 53735 3526/ceph-mon
root@hpv-prx-01:~# netstat -lptune | grep 3300
tcp 0 0 10.254.94.196:3300 0.0.0.0:* LISTEN 64045 53734 3526/ceph-monNous avons donc ici bien le protocl réseau v2 (port 3300) activé.
ceph mon enable-msgr2Cela indiquera à tous les moniteurs qui se lient à l'ancien port par défaut 6789 pour le protocole v1 hérité de se lier également au nouveau port de protocole 3300 v2. Pour voir si tous les moniteurs ont été mis à jour, exécutez
ceph mon dumpet vérifiez que chaque moniteur a une adresse v2 : et v1 : répertoriée.
Préparation sur chaque nœud de cluster Ceph
Modifiez les référentiels Ceph actuels d'Octopus à Pacific.
sed -i 's/octopus/pacific/' /etc/apt/sources.list.d/ceph.listVotre /etc/apt/sources.list.d/ceph.list devrait maintenant ressembler à ceci
deb http://download.proxmox.com/debian/ceph-pacific bullseye mainDéfinir le drapeau « noout »
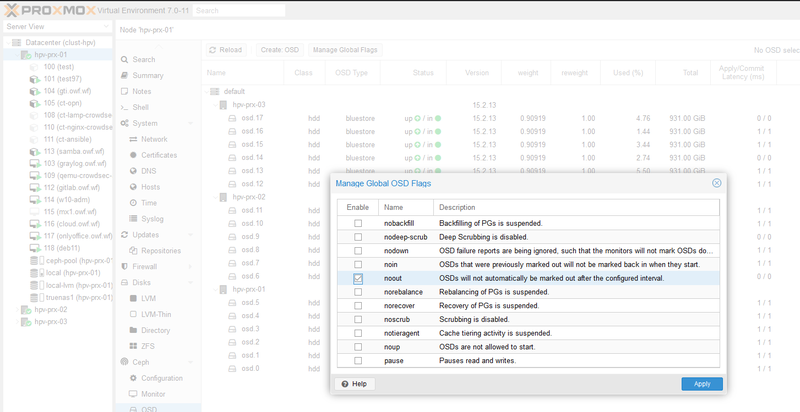
Définissez l'indicateur noout pour la durée de la mise à niveau (facultatif, mais recommandé) :
ceph osd set nooutOu via l'interface graphique dans l'onglet OSD (Gérer les indicateurs globaux).
Mettre à niveau sur chaque nœud de cluster Ceph
Mettez à niveau tous vos nœuds avec les commandes suivantes. Il mettra à niveau le Ceph sur votre nœud vers Pacific.
apt update
apt full-upgradeAprès la mise à jour, votre configuration exécutera toujours les anciens binaires Octopus.
Redémarrer le démon de surveillance
Après la mise à niveau de tous les nœuds du cluster, vous devez redémarrer le moniteur sur chaque nœud sur lequel un moniteur s'exécute.
systemctl restart ceph-mon.targetUne fois que tous les moniteurs sont en place, vérifiez que la mise à niveau du moniteur est terminée. Recherchez la chaîne Pacific dans la carte mon. La commande
ceph mon dump | grep min_mon_releasedevrait signaler
min_mon_release 16 (pacific)Si ce n'est pas le cas, cela implique qu'un ou plusieurs moniteurs n'ont pas été mis à niveau et redémarrés, et/ou que le quorum n'inclut pas tous les moniteurs.
Redémarrez les démons du gestionnaire sur tous les nœuds
Redémarrez ensuite tous les gestionnaires sur tous les nœuds
systemctl restart ceph-mgr.targetVérifiez que les démons ceph-mgr sont en cours d'exécution en vérifiant ceph -s
ceph -s...
services:
mon: 3 daemons, quorum foo,bar,baz
mgr: foo(active), standbys: bar, baz
...Redémarrez le démon OSD sur tous les nœuds
Il est préférable de redémarrer les OSD sur un nœud à la fois après
systemctl restart ceph-osd.targetAttendez après chaque redémarrage et vérifiez périodiquement l'état du cluster :
ceph statusIl doit être dans HEALTH_OK ou
HEALTH_WARN
noout flag(s) setFacultatif : Vous pouvez désactiver la conversion automatique des données OMAP avec :
ceph config set osd bluestore_fsck_quick_fix_on_mount falseMais la conversion doit se faire le plus tôt possible.
Interdire les OSD pré-Pacific et activer toutes les nouvelles fonctionnalités uniquement pour le Pacific
ceph osd require-osd-release pacificREMARQUE : Le fait de manquer cette étape interrompt le démarrage de l'OSD à partir duquel ils ont leur version requise sur Ceph Luminous ou une version antérieure (par exemple, si vous avez effectué une mise à niveau de Luminous -> Nautilus -> Octopus)
Mettre à niveau tous les démons CephFS MDS
Je n'ai donc pas pu tester cette partie.
Pour chaque système de fichiers CephFS,
- Assurez-vous qu'un seul MDS est en cours d'exécution
L'installation par défaut utilise un MDS actif. Pour vérifier si c'est le cas sur votre cluster, vérifiez la sortie de ceph status et vérifiez qu'il n'y a qu'un seul MDS actif.
Réduisez le nombre de rangs à 1 (si vous prévoyez de le restaurer plus tard, notez d'abord le nombre d'origine de démons MDS). :
ceph status
ceph fs get <fs_name> | grep max_mds
ceph fs set <fs_name> max_mds 1- Attendez que le cluster désactive tous les rangs non nuls en vérifiant périodiquement l'état :
statut ceph- Mettez tous les démons MDS de secours hors ligne sur les hôtes appropriés avec :
systemctl stop ceph-mds.target- Confirmez qu'un seul MDS est en ligne et qu'il est au rang 0 pour votre FS :
ceph status- Mettez à niveau le dernier démon MDS restant en redémarrant le démon :
systemctl restart ceph-mds.target- Redémarrez tous les démons MDS de secours qui ont été mis hors ligne :
systemctl start ceph-mds.target- Restaurez la valeur d'origine de max_mds pour le volume :
ceph fs set <fs_name> max_mds <original_max_mds>Désactivez le drapeau 'noout'
Une fois le processus de mise à niveau terminé, n'oubliez pas de désactiver le drapeau noout.
ceph osd unset nooutOu via l'interface graphique dans l'onglet OSD (Gérer les indicateurs globaux).
Mettre à niveau les paramètres
Pour ma part j'ai réalisé un upgrade de Octopus vers Pacific donc je n'ai pas eu à faire cette partie.
Si vos paramètres CRUSH sont plus anciens que Hammer, Ceph émettra désormais un avertissement de santé. Si vous voyez une alerte sanitaire à cet effet, vous pouvez annuler cette modification avec :
# move to older minimum required version, only required if ceph complains
ceph config set mon mon_crush_min_required_version fireflySi Ceph ne se plaint pas des anciens paramètres CRUSH, nous vous recommandons de basculer également tous les seaux CRUSH existants vers paille2, qui a été rajouté dans la version Hammer. Si vous avez des seaux de paille, cela entraînera une quantité modeste de mouvement de données, mais généralement rien de trop grave :
# create a backup first
ceph osd getcrushmap -o backup-crushmap
ceph osd crush set-all-straw-buckets-to-straw2S'il y a des problèmes, vous pouvez facilement revenir en arrière avec :
ceph osd setcrushmap -i backup-crushmapLe passage aux seaux paille2 débloquera quelques fonctionnalités récentes, comme le mode d'équilibrage compatible avec l'écrasement rajouté dans Nautilus.
Problèmes connus
Repartitionnement RocksDB cassé
La configuration du repartitionnement RocksDB après la mise à niveau est actuellement interrompue (16.2.4) et nécessitera la suppression et le rajout de l'OSD. Veuillez éviter de déclencher un reshard jusqu'à nouvel ordre ici.
Surveiller les plantages après la mise à niveau
Pour les anciens clusters (pré-jewel) qui n'utilisaient pas CephFS, il se peut que le moniteur plante une fois mis à jour vers Pacific en raison de certaines anciennes structures de données qu'il ne comprend toujours pas. Suivez la solution de contournement dans le suivi des bogues Ceph ou attendez que Ceph Octopus v15.2.14 puisse être installé avant de passer à Pacific.